We introduce NitroGen, a vision-action foundation model for generalist gaming agents that is trained on 40,000 hours of gameplay videos across more than 1,000 games. We incorporate three key ingredients: 1) an internet-scale video-action dataset constructed by automatically extracting player actions from publicly available gameplay videos, 2) a multi-game benchmark environment that can measure cross-game generalization, and 3) a unified vision-action policy trained with large-scale behavior cloning. NitroGen exhibits strong competence across diverse domains, including combat encounters in 3D action games, high-precision control in 2D platformers, and exploration in procedurally generated worlds. It transfers effectively to unseen games, achieving up to 52% relative improvement in task success rates over models trained from scratch. We release the dataset, evaluation suite, and model weights to advance research on generalist embodied agents.
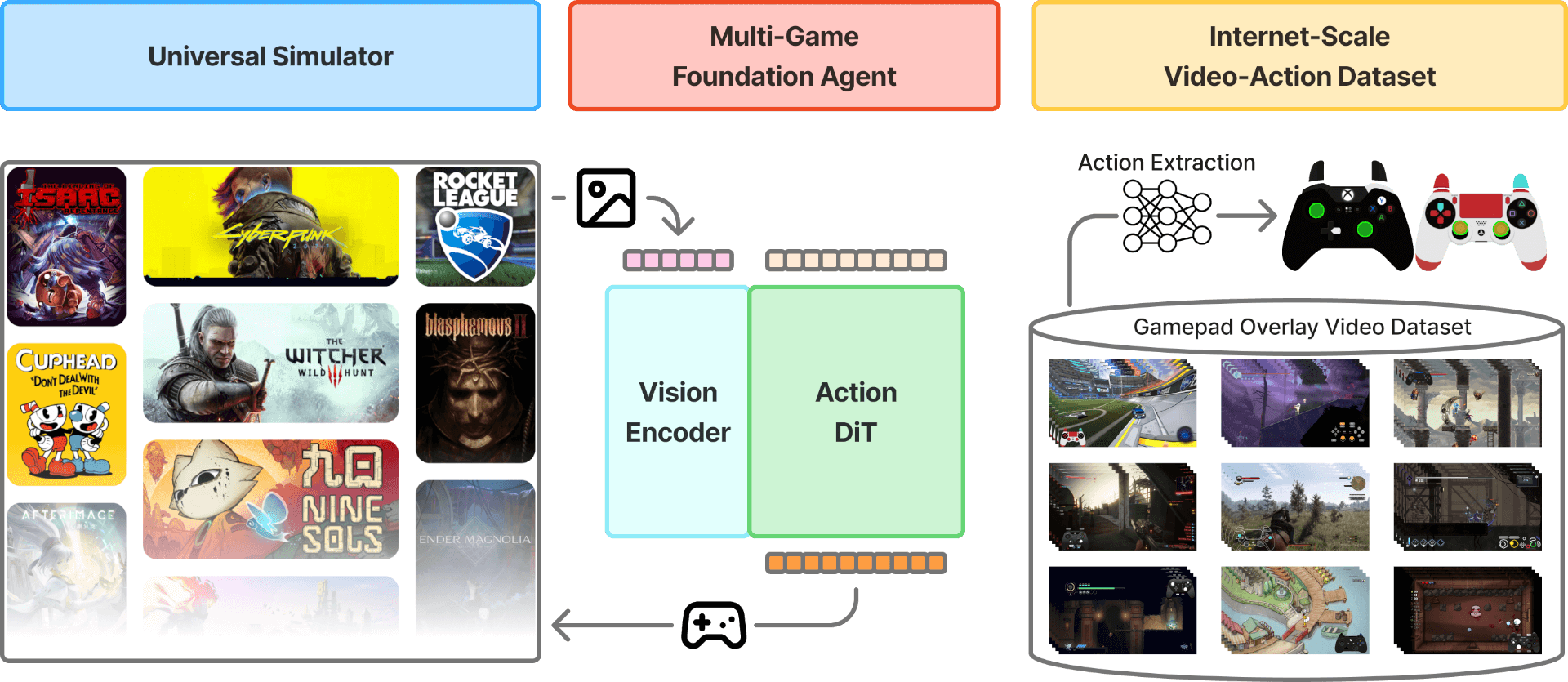
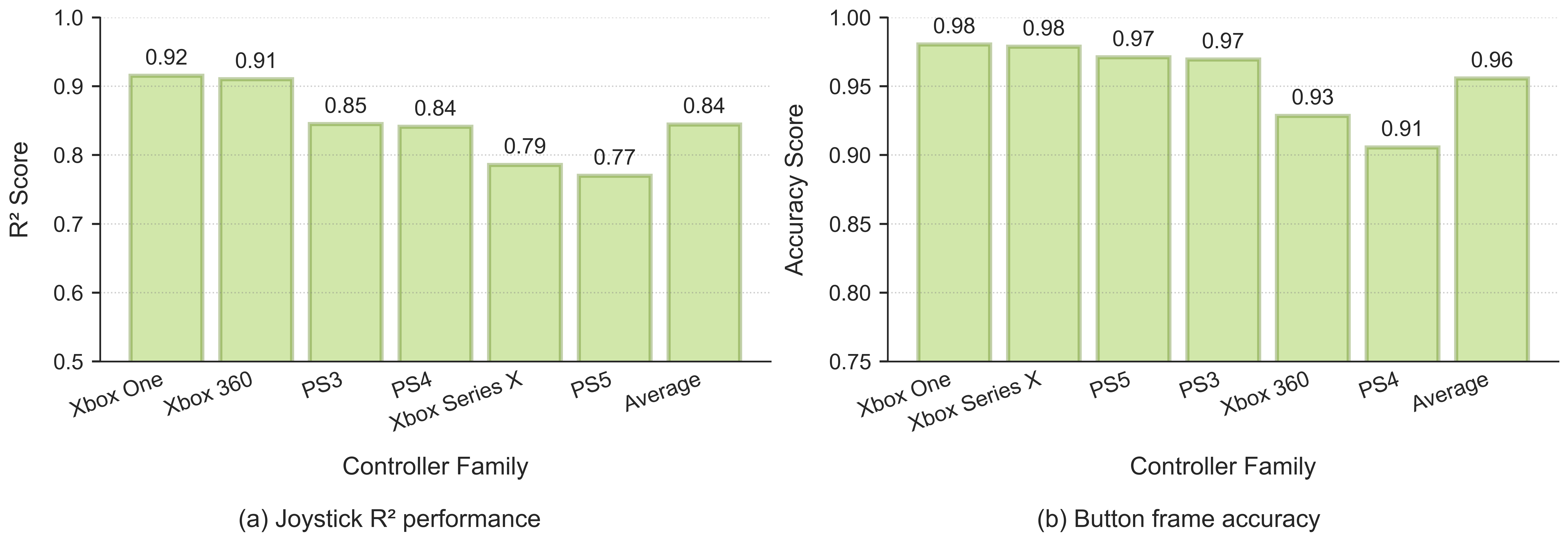

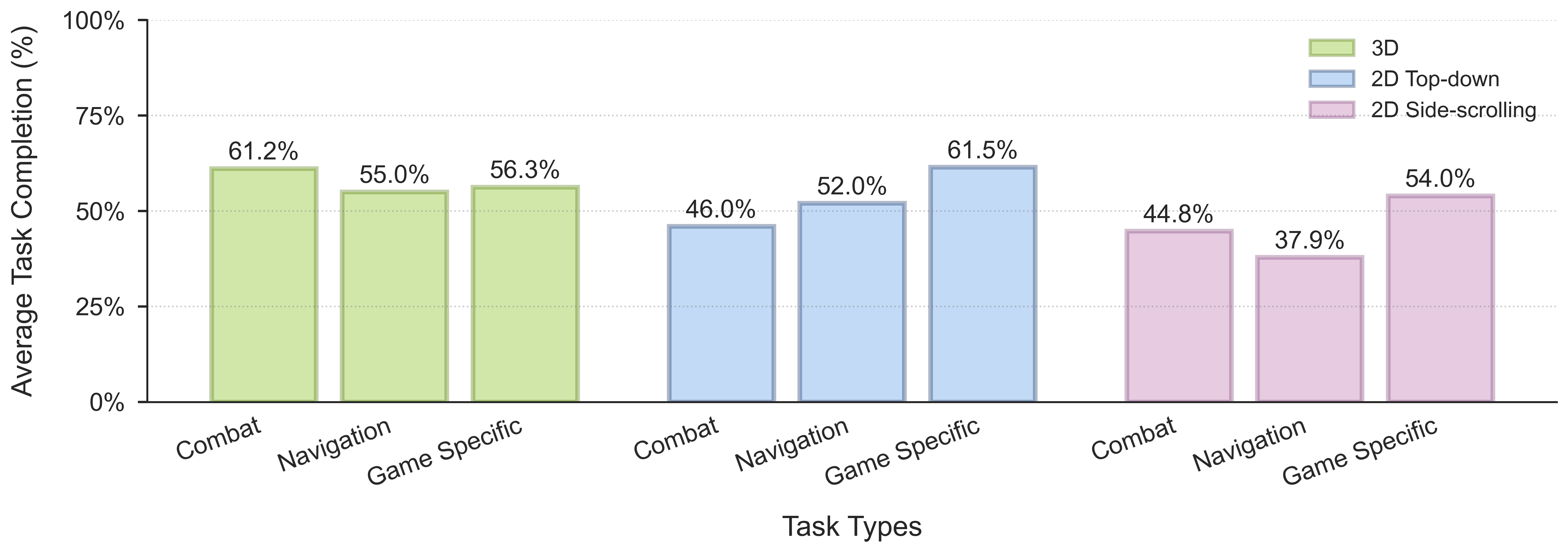
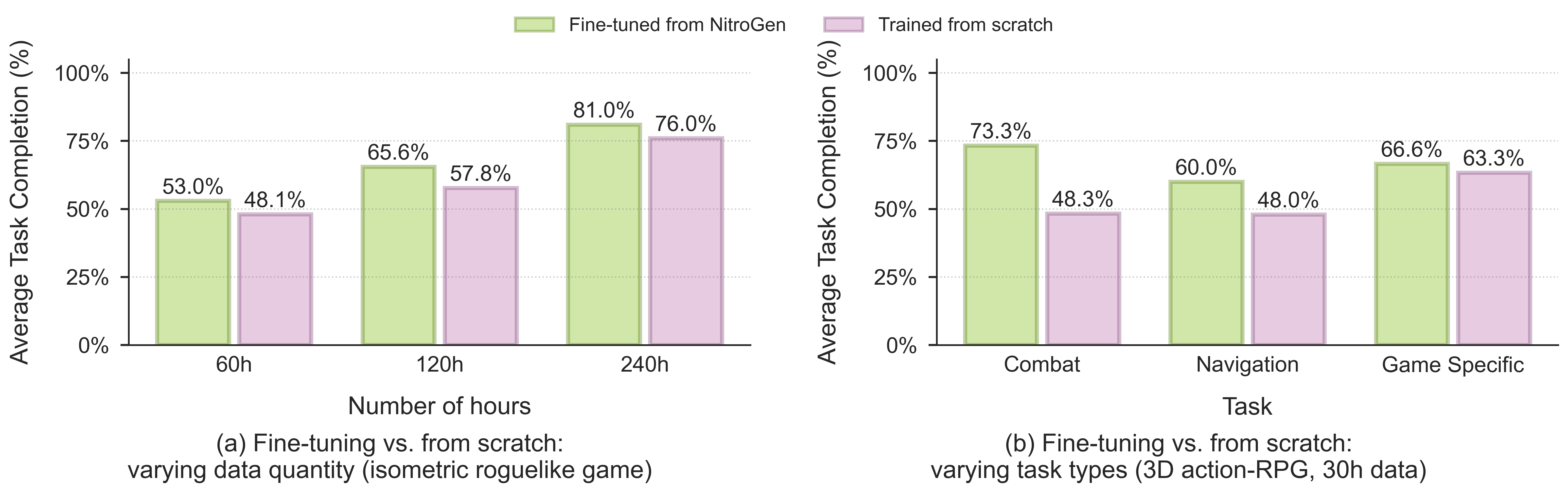
In this work, we introduce NitroGen, an approach to scale up foundation pre-training for video game agents and demonstrate how internet pre-training can yield a generalist policy. We leverage a new source of publicly available data to build an internet-scale video-action dataset, and empirically demonstrate its effectiveness by successfully training a multi-game policy. NitroGen shows positive signs of generalization in fine-tuning experiments. By lowering the barrier to train agents on new environments, NitroGen serves as a starting point to develop more powerful and general-purpose agents.
 Loïc Magne *
Loïc Magne *
 Anas Awadalla *
Anas Awadalla *
 Guanzhi Wang * †
Guanzhi Wang * †
 Yinzhen Xu
Yinzhen Xu
 Joshua Belofsky
Joshua Belofsky
 Fengyuan Hu
Fengyuan Hu
 Joohwan Kim
Joohwan Kim
 Ludwig Schmidt
Ludwig Schmidt
 Georgia Gkioxari
Georgia Gkioxari
 Jan Kautz
Jan Kautz
 Yisong Yue †
Yisong Yue †
 Yejin Choi †
Yejin Choi †
 Yuke Zhu †
Yuke Zhu †
 Linxi "Jim" Fan †
Linxi "Jim" Fan †
* Co-lead † Co-advise
@misc{magne2026nitrogen,
title={NitroGen: An Open Foundation Model for Generalist Gaming Agents},
author={Loïc Magne and Anas Awadalla and Guanzhi Wang and Yinzhen Xu and Joshua Belofsky and Fengyuan Hu and Joohwan Kim and Ludwig Schmidt and Georgia Gkioxari and Jan Kautz and Yisong Yue and Yejin Choi and Yuke Zhu and Linxi "Jim" Fan},
year={2026},
eprint={2601.02427},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2601.02427},
}
